战术建模(Tactical Modeling)
战术建模是指设计DDD中的组成构造块,比如实体、值对象、聚合、领域服务、领域事件、模块、资源库、应用服务等。
实体(Entity)
在面向对象的开发模式中,一个类会封装对象属性以及相应的操作,这时我们如果需要区分不同的类对象,便会引入一个身份标识,不同身份标识的对象完全是两个东西。
而在领域驱动设计中,我们称能够区分的不同对象为实体。实体在生命周期中可以对内部属性进行任何的修改,但是修改后的实体依然认为是同一个实体。
根据上述描述,实体有两个重要的特点:1. 唯一身份标识(Unique Identity);2.可变性(Mutability Characteristics)。
有了实体这个概念后,有一个重要的问题就是怎么来创建实体的身份标识。《实现领域驱动设计》一书中给除了几种常用的方法:
(1)由户提供初始值唯一值
比如微信注册由用户提供微信号的方式。
这种方式非常直接,但却十分依赖于用户提供的高质量标识,这也是后期导致复杂性的原因之一。
比如后期用户想修改标识或许将是一件十分困难的事情。
(2)程序内部通过某种算法自动生成
比如UUID和GUID。这些可以通过如java.util.UUID库或者Snowflake等唯一ID生成算法。
不过需要注意的是,一般建议用值对象来维护一个唯一标识,因为唯一标识里面可能会有一些额外的细节信息,这些信息可以通过值对象接口暴露给外部。
PS:程序生成唯一标识建议在资源库中实现。
(3)持久化存储机制生成
比如Mysql的自增ID。
在实践中,可以定义一张表专门用于生成自增ID。
(4)由另外一个限界上下文生成
比如内部业务系统会使用某个限界上下文的已经定义好的标识。
举个栗子:用户通过输入手机号后,可以根据这个手机号查找用户唯一标识。
在解决了唯一标识的生成方法后,下面一个需要解决的问题就是何时生成了。一般会有如下时间节点:
(1)持久化前
在持久化之前如果你需要唯一标识来完成一些工作(比如对外发布领域事件),那么你必须在持久化前就生成唯一标识。
(2)持久化后
比如完全采用数据库来帮助你生成唯一标识。
最后,唯一标识一旦生成,多数情况下都不应该被修改,也就是需要在整个实体生命周期中保持标识的稳定性。
确保实体唯一的问题解决后,最重要的就是丰富实体的属性和行为了,在战略建模中,整个团队已经开发出了通用语言,其中有动词、名词、形容词。从这些词语之中,我们便能分析出某个限界上下文有哪些实体以及这些实体需要进行哪些行为。
比如有一句:用户可以给自己的好友发送短消息。
从这句话中,我们可以提取出名词:用户、好友、短消息;动词:发送。
根据上面这句话,这里肯定存在一个实体:用户。
然后就是根据通用语言设计实体属性,再接下来就是挖掘实体的关键行为。
比如用户有一个好友列表、有手机号等,这些都是用户属性。
用户可以添加好友,可以删除好友,可以给好友发消息,这些都是用户实体的关键行为。
通过不停的沟通讨论以及随着团队对模型了解的深入,实体的内容也将会越来越丰富。
由于实体一般是通过一些传入参数进行创建,为了保证实体各种属性的有效性,一般需要验证属性值的合法性,或者说验证整个对象的合法性。
验证方法可以在构造函数中验证,如果验证过程非常复杂,那么也可以通过一定义一些辅助验证Handler来辅助校验,甚至可以用一个领域服务来进行验证。
值对象(Value Object)
在上节实体中我们提到了实体两个重要的特点:唯一和可变性。其中唯一含义是就算实体其他属性完全一样,只要唯一标识不一样依然认为是两个不同的实体;可变则意味着实体内部属性可以被修改。
而值对象则刚好相反:不变性和无唯一标识。不变代表值对象不会单独修改对象的某个属性,而是做整体替换;无唯一标识则意味着只要值对象属性全部相等,那么就认为是同一个值对象。
也正是由于值对象的不变性,因此值对象拷贝可以采用浅拷贝的方式。
值对象的这个特点可以简化对值对象的使用。不变意味着我们可以不用担心对值对象的修改,可以认为是一个无害的对象。
《实现领域驱动》一书中对于是否应该建模成值对象给了一些原则:
(1)It measures, quantifies, or describes a thing in the domain.
(2)It can be maintained as immutable.
(3)It models a conceptual whole by composing related attributes as an integral unit.
(4)It is completely replaceable when the measurement or description changes.
(5)It can be compared with others using Value equality.
(6)It supplies its collaborators with Side-Effect-Free Behavior.
一般在实践中,一个值对象表示一个完整的概念,比如地址是一个完整的概念,其由国家、省、市字段组成,这时把地址建模成一个值对象是合理的。
在值对象上面定义的方法都是无副作用函数(Side-Effect-Free Function),也就是任何方法都不能修改值对象内部的状态,在C++中可以理解为所有函数都是const函数。
除了在自己的限界上下文使用值对象外,在进行上下文集成时,也尽量通过值对象去建模其他上下文的概念,也就是所谓的最小化集成(Integrate with Minimalism)。
聚合(Aggregate)
为什么要使用聚合?聚合是用来组成一致性边界的,所有的操作都是在聚合上实现的,聚合内部再协调实体、值对象完成相应的操作。
聚合设计过大过小都会出现问题。聚合过大可能会导致并发下降,其本身也十分臃肿;聚合过小则可能会导致无法保证领域内对象的状态一致性。
在《实现领域驱动设计》一书中给出了几个设计聚合的原则:
(1)Model True Invariants in Consistency Boundaries
在一致性边界之内建模真正的不变条件。不变条件表示一个业务规则始终是一致的(An invariant is a business rule that must always be consistent)。
一致性在这里主要是事务一致性,也就是说在持久化中使用单事务来管理聚合的一致性,即在一个事务中只会修改一个聚合。
(2)Design Small Aggregates
设计小聚合,这个也符合软件世界的复杂问题分解成简单小的问题来解决。正如前面所说,聚合过大可能会导致持久化性能受到影响,也有可能会影响将聚合加载到内存的速度。
(3)Reference Other Aggregates by Identity
通过唯一标识引用其他聚合。不要采用组合的方式直接引用其他聚合,而是采用唯一标识的方式,这样也间接表明我们不会在一个事务中修改多个聚合。
在实践中可以在应用服务中来处理聚合的依赖关系,以避免在聚合中使用资源库或者领域服务。
(4)Use Eventual Consistency Outside the Boundary
在聚合外界之外使用最终一致性。上面写到不要在一个事务中修改多个聚合,那么如果用户命令确实需要多个聚合的情况下,可以通过消息来使得多个聚合最终一致。最终一致会存在一定的延迟,这个需要考虑能否接受这个延迟。
关于使用事务一致或者最终一致,有一个原则可供参考:
When examining the use case (or story), ask whether it’s the job of the user
executing the use case to make the data consistent. If it is, try to make it transactionally consistent,
but only by adhering to the other rules of Aggregates.
If it is another user’s job, or the job of the system, allow it to be eventually consistent.
虽然原则是一个很好的参考标准,但是软件开发总有例外,如果要打破上述原则,那么可能需要有一些充足的理由:
(1)User Interface Convenience
为了用户方便,也就是用户为本。
(2)Lack of Technical Mechanisms
缺乏技术机制,毕竟巧妇难为无米之炊。
(3)Global Transactions
需要全局事务,在很多金融领域可能会用到。
(4)Query Performance
为了查询性能,妥协与平衡的艺术。
领域服务(Domain Service)
领域服务应当是无状态的,当某个操作不适合放在聚合、实体或者值对象上,这时候可以采用领域服务。和应用服务不同,领域服务是含有业务逻辑的。
一般而言,领域服务并不意味着一定需要远程、重量级的事务操作。
书中给出了一些判断一个操作是否需要用领域服务来承载的思考点:
(1)Perform a significant business process (2)Transform a domain object from one composition to another (3)Calculate a Value requiring input from more than one domain object
在具体实践中,不要过度使用领域服务,而是在必要的时候才使用,否则可能导致贫血模型。至于怎么判断是否需要使用领域服务,除了参考上面的准则,也会随着团队对模型的进一步深入理解而发生变化。
在编码过程中,判断某个操作是否适合放在实体或者聚合里面可以借鉴面向对象编程的SOLID原则,如果有可能违背,那么这时候就可以考虑是否应该放在领域服务中了。
领域事件(Domain Event)
领域事件,就是领域专家所关心的发生在领域中的一些事件,比如对于微信注册,领域专家可能关心用户注册成功这一个事件,那么注册成功就可以认为是领域事件。
领域事件产生后,可能是本限界上下文消费,也有可能是被其他限界上下文消费。下图为《实现领域驱动设计》一书中领域事件一个抽象的流转图:
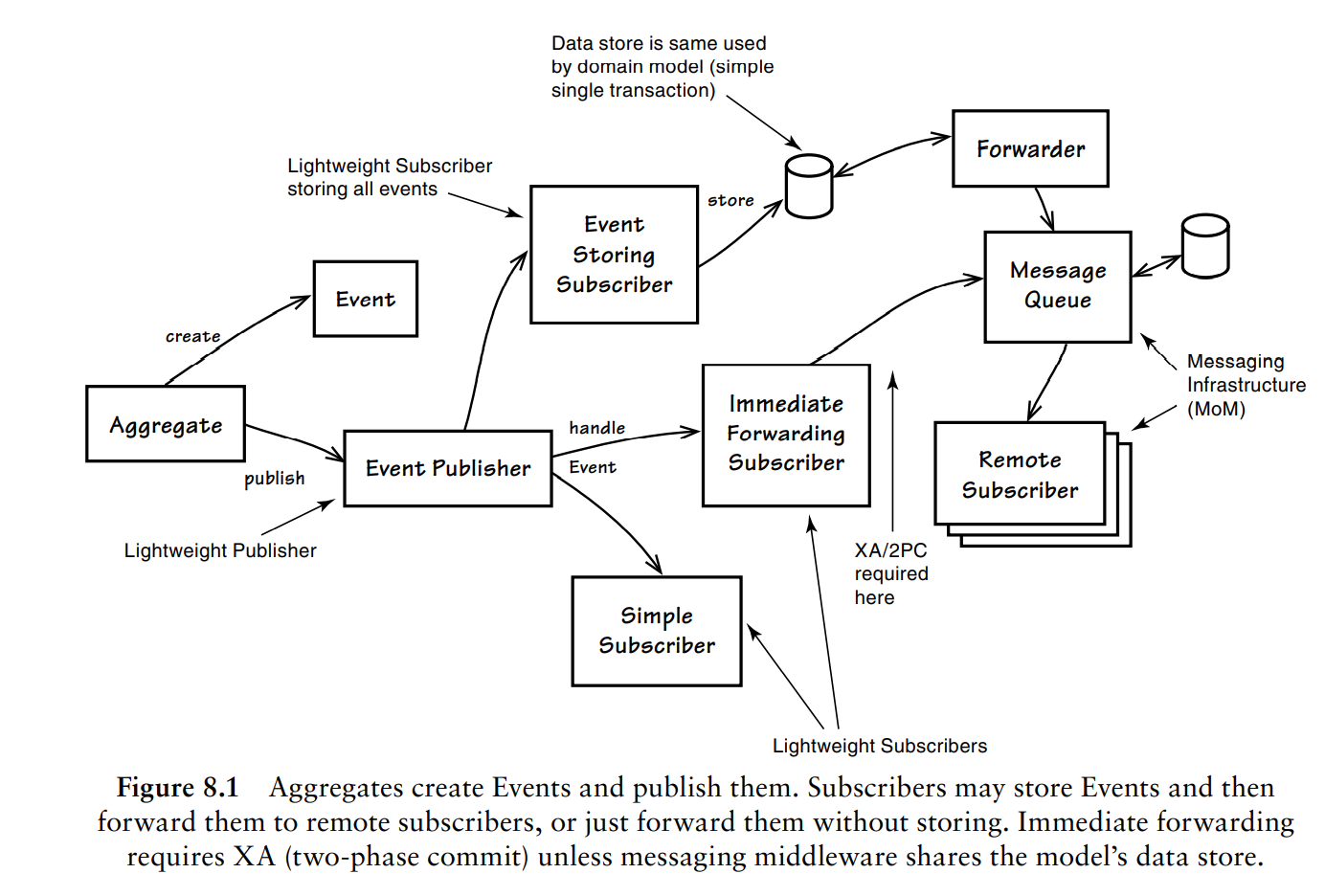
图中领域事件由聚合发布,经过转储最后被远端订阅者消费。
领域事件可以用来简化系统,将一些系列的操作拆分成多个粒度较小的处理单元。
有一些领域事件如果不是由聚合中的命令操作产生的,那么可以把事件建模成一个聚合,同时可以拥有自己的资源库。这种领域事件可以由领域服务产生,然后添加到资源库中后由消息基础设施进行发布。
一般而言,领域事件建模成聚合后需要生成一个唯一的事件标识,实践中这个唯一标识可能是根据属性计算得到的。
对于本地发布以及消费,可以使用观察者模式,同时在应用服务中注册订阅者。
对于远端订阅者,基础设施可能会提供消息中间件,并且通过两段式事务完成领域事件的发布(因为需要保证聚合持久化存储以及消息中间件持久化存储的最终一致),然后由消息中间件推送领域事件给注册的订阅者。
最后关于领域事件要说的就是事件去重。事件去重包含两层含义:1.发布者去重;2.消费者去重。
发布者去重主要是发布者能通过一定的手段方式重复发送消息,比如通过消息的唯一标识来去重;消费者去重一般是指消费者能够做到消费多条一样的消息最后结果是一样的,也就是消费是幂等的。
模块(Modules)
在DDD中,模块可以理解为组织模型代码的方式,也就是各种类是怎么组织保存的。模块可以理解为某些编程语言里面的包或者命名空间。在设计模块名的时候,应该能充分反映领域中的概念,或者说反映通用语言。
下面是《实现领域驱动设计》一书中设计模块的简单原则:


设计模块及其命名需要给予与设计实体、值对象等领域模型同样的重视程度,保持模块的整洁。
如果借用C++中的namespace概念,那么一个模块组织如下(假设公司域名awesome.com):
namespace com {
namespace awesome {
namespace context_boundary_a {
namespace domain {
namespace model {
// 这里定义实现实体、聚合、值对象、领域事件等领域对象
}
namespace service {
// 这里定义实现领域服务
}
namespace application {
// 这里定义实现应用服务
}
namespace infrastructure {
// 这里定义实现基础设施层比如资源库
}
namespace adapter {
// 这里定义实现一些端口适配器
}
}
}
}
}
如果在战略建模的过程中有一些概念没办法很好的分离到不同的限界上下文中,那么可以先放在一起并通过模块的方式来划分。
资源库(Repository)
资源库对于领域模型来说可以抽象理解为是一个可以安全存放领域对象的区域,也就是聚合可以通过资源库持久化以及从资源库获取聚合。
通常来说,每一种聚合都将拥有一个资源库,也就是一对一的关系。
一般来说,一个资源库会在领域模型层定义相关接口,然后在基础设施层实现这个接口,由于聚合是有唯一标识的,那么资源库接口设计一般是这样的:
class SomeAggregateRepository {
public:
SomeAggregate FindSomeAggregateOfId(SomeAggregateId id);
void SaveSomeAggregate(const SomeAggregate &agg);
};
在上面的SaveSomeAggregate函数可以完成数据库数据的创建或者修改。
资源库通过依赖注入的方式注入领域层,这样也比较方便进行单元测试。
集成限界上下文
一个项目会存在多个限界上下文,这个会体现在战略建模中的上下文映射图。而为了完整整个项目,需要集成这些限界上下文。
《实现领域驱动设计》一书中给出了多个集成的方式:
(1)Integration Using RESTful Resources
一个上下文通过URI方式提供REST资源,而客户端则可以通过防腐层来访问这些资源,类似下图:
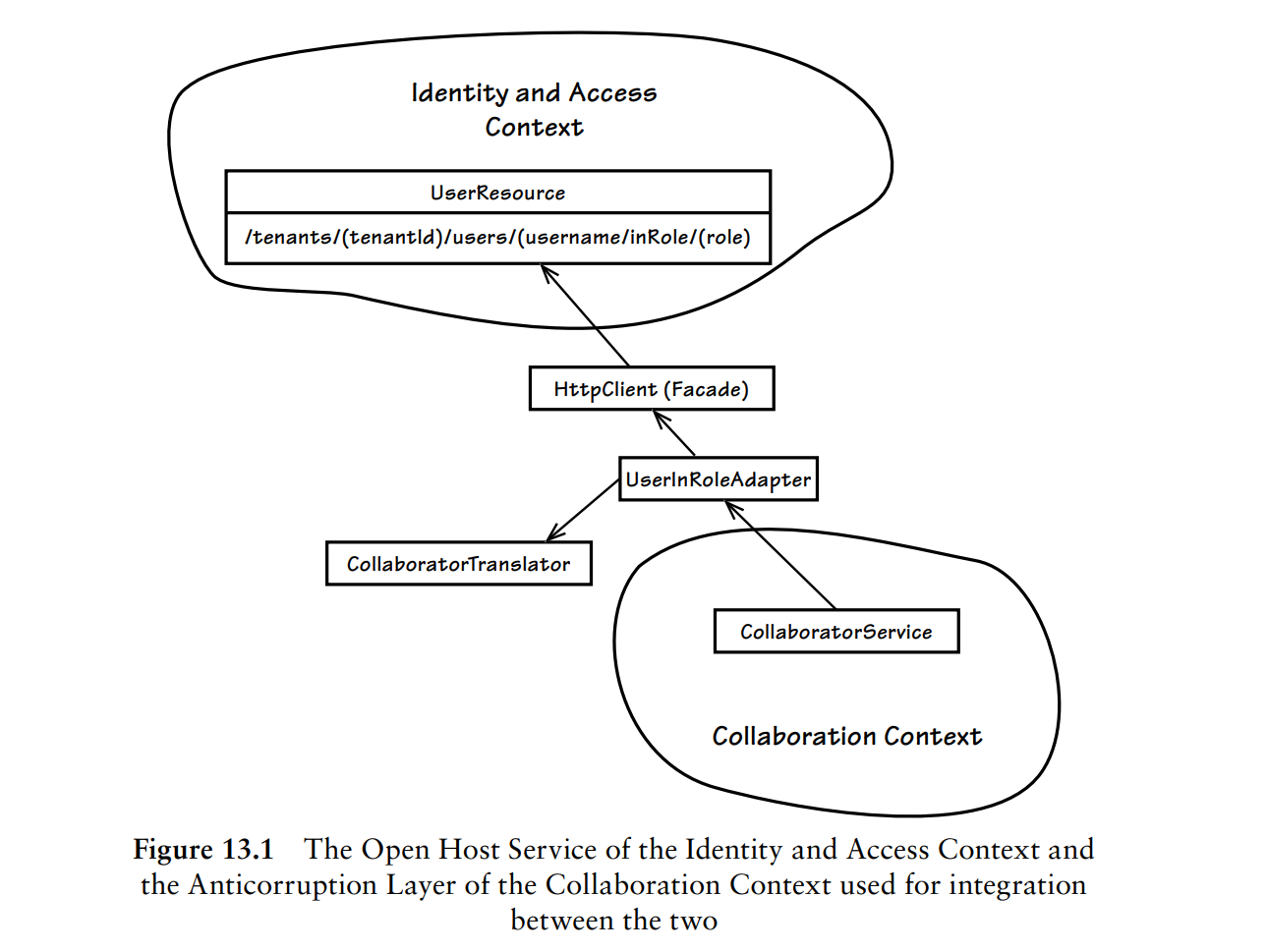
通过防腐层将依赖限界上下文的概念翻译成本地的值对象。
(2)Integration Using Messaging
通过领域事件来集成,该方式可以增强系统自洽性。
进一步了解
- Groovy
- Grails
- Ruby on Rails
- Apache Commons
- Riak
- MongoDB
- Qi4j
- ActiveMQ
- RabbitMQ
- Akka
- NserviceBus
- MassTransit
- Life beyond Distributed Transactions: an Apostate's Opinion