排序算法汇总
- 插入排序:插入排序思想是通过逐遍扫描(N-1遍扫描,N为排序元素个数)的方式消除逆序对,对于位置P=1遍到P=N-1遍保证插入顺序位置0到位置P为已排序状态。
- 冒泡排序:通过重复遍历待排序的数列,每次比较一对元素,过程中不断消除逆序对,最终达到排序的目的,和插入排序对比,冒泡排序每次遍历结束后已排序的数列元素个数至少+1
- 选择排序:每次遍历找到未排序序列的最大或者最小值,将其插入已排序队列的末尾,一般需要N-1趟遍历,因此选择排序移动元素次数很少,至多为N-1次
- 归并排序:归并排序是分治法的典型应用之一,分治法解决问题主要步骤为:分解,将原问题分解成一系列子问题;解决,递归地解各子问题,若子问题足够小,则直接求解;合并,将子问题的解合并成原问题的解。归并排序分解动作为将数组分为两半;递归解规模为N/2的子问题,最终分解成只有一个元素的子问题;最后将子问题解合并得到最终排序的序列
- 快速排序:快速排序和归并排序一样,也是采用分治思想,不过其分解思路为将数组分解为以某一基准值的两部分,使得一部分序列的所有元素都小于等于该基准值,另一部分序列的所有元素都大于该基准值(实际和基准值相等的元素可以放到任何一部分)。递归地分解直到分解序列元素个数为0或1。最后合并子问题解得到原问题解
- 计数排序:计数排序的基本思想为对每个序列元素x,确定小于等于x的元素的个数m,从而根据m确定元素的排序后的位置。其基本流程可归纳如下:找出序列的最大最小值,确定k值;定义数组Count[0~k],统计序列中值为i的元素的个数并存入Count[i]中;计算Count[i]=Count[i]+Count[i-1];反向填充目标排序数组,将每个元素放入数组的第Count[i]项,同时Count[i]值减1
- 基数排序:基数排序的原理是将整数按位切割成若干数字,按照每位数分别比较,最终合并成有序的序列
- 桶排序:桶排序的基本思想是将待排序序列分到数量有限的桶中,然后对每个桶分别排序,最后将各个桶中的数据有序地合并起来
- 希尔排序:希尔排序是递减增量排序算法,是插入排序更高效的改进版本,其基本思想为通过将比较的元素根据增量序列分为若干区域,然后对若干区域进行直接插入排序,随着增量序列减少到1时,进行最终的插入排序
- 堆排序:堆排序的基本原理是利用堆这种数据结构完成排序,通过不断的删除堆顶元素和调整堆,最终得到有序的序列
- 鸡尾酒排序:鸡尾酒排序也称为定向冒泡排序,是冒泡排序的一种变形,主要区别在于排序时是以双向在序列中排序,即大值往上交换时小值往下交换
各排序算法的时间复杂度和空间复杂比较如下表:
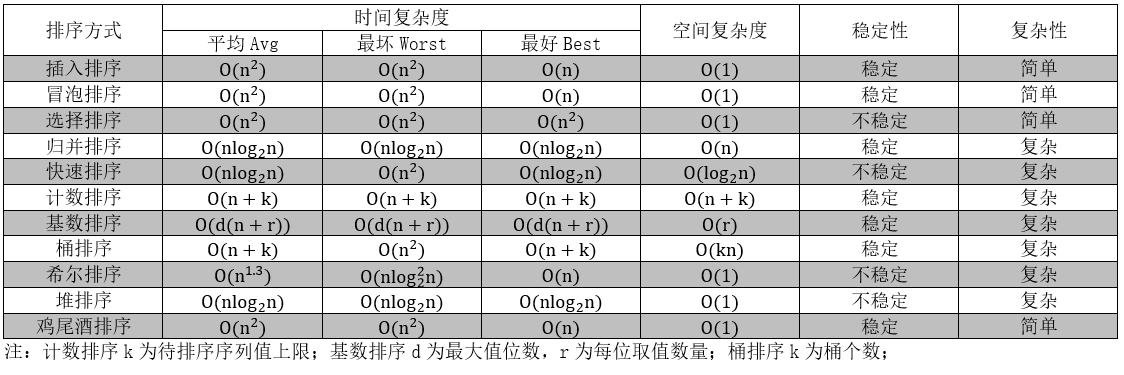
以下分别分析实现各大算法。
插入排序
插入排序是基于比较的排序,其基本原理是在初始状态前1个元素是有序的,然后每次将后方的一个元素插入前方的有序段并保持有序,当最后一个元素插入完成时,整个序列保持有序。其时间复杂度可以通过简单的计算得出,我们不妨假设每趟元素至少需要和有序元素段的一半元素进行比较,则时间复杂度可为1/2+1+3/2+4/2….+(N-1)/2=(N-1)N/4=O(N2);最差时间就是1+2+3+N-1=(N-1)N/2=O(N2);最好的就是每次只需和有序队列比较一个元素就可以确定位置,即输入序列即为有序,此时时间复杂度为1+1+1+….(n-1个)=N-1=O(N)。插入排序除了几个变量外无需额外空间,因此空间复杂度为O(1)。下面为插入排序的实现,采用模板编程方式实现。
1 | //非递减 |
有一道腾讯笔试题即可采用该算法思想完成,题目见下:
腾讯笔试题“字符移位”
小Q最近遇到了一个难题:把一个字符串的大写字母放到字符串的后面,各个字符的相对位置不变,且不能申请额外的空间。你能帮帮小Q吗?
输入描述:输入数据有多组,每组包含一个字符串s,且保证:1<=s.length<=1000.
输出描述:对于每组数据,输出移位后的字符串。
输入输出示例:输入AkleBiCeilD,输出kleieilABCD。
此题只要对于小写字母,只要往前移动知道遇到小写字母或者移动到首位置即可停止,代码见下:
1 | void MoveChar(string &inputString) |
冒泡排序
冒泡排序的过程非常类似于自然界上浮现象,从第一个元素开始,依次和后一个元素比较,如果大,则交换,直到上浮到顶端,其时间复杂度分析和插入排序类似但是由于需要一路比较直到顶部,因此冒泡算法的时间复杂度最坏和平均情况都需要一直交换到顶端,因此为N-1+N-2+…..1=(N-1)N/2,而最好时间复杂度可以通过设置一个标志位达到O(N),否则按照常规无标志位的最好依然需要O(N2),冒泡排序空间复杂度和插入排序一样为O(1)。标志位原理如下代码所示:
1 |
|
选择排序
选择排序的原理是在未排序的序列找到一个最小值,插到已排序序列第的末尾。在第一遍历时找到最小值,第二次找多第二小值,经过N-1趟遍历可以排好N-1个元素,最后一个元素肯定处在正确位置。由于选择排序每次都要遍历整个未排序序列,故其最好与最坏时间复杂度均为N+N-1…..2=(N+2)(N-1)/2=O(N2),其基本代码如下所示:
1 |
|
归并排序
归并排序是分治法经典的应用之一,归并排序通过将问题划分为两个大小相似的问题分别求解,然后合并两部分解得到最后的解,其时间复杂度递推关系式为T(N)=2T(N/2)+N(T(1)=1);其中N代表在合并解时花费的时间,即合并两个序列的总大小。在求解这个关系式时,可以两边同时除以N,有T(N)/N=T(N/2)/(N/2)+1,而T(N/2)/(N/2)=T(N/4)/(N/4)+1….T(2)/2=T(1)+1。所有左边相加,所有右边相加有T(N)/N=T(1)+log2N,推出T(N)=Nlog2N+N=O(Nlog2N),归并排序由于需要一个附加的数组保存归并结果,因此空间复杂度为O(N),递归栈空间为log2N。归并排序有两种算法,递归和非递归,递归版算法代码分别如下:
1 |
|
快速排序
快速排序和归并排序的基本思想都是分治法,不过快速排序划分子问题是以一个元素为基准,小于该元素的放在一边,大于的放在另外一边,通过这样的递归划分,最终递归只剩一个元素时返回,由于每次分割排序后分割元素都在正确位置,因此该算法最终将会使整个序列有序。由于快速排序分割元素选取是不固定的,一般有固定选取头部或者尾部(如果原始有序则时间复杂度很差)、随机选取和三数中值分割法等。快速排序最好时间复杂度产生在每次都均分数组,此时时间复杂度为O(Nlog2N),而最差发生在每次将数组分割成1个元素和剩余的元素,此时时间复杂度为O(N2)。在空间复杂度上,由于快速排序可以不借助额外空间进行原地交换,因此其空间复杂度为栈空间复杂度log2N,最差空间复杂度为O(N)。和归并排序一样,快速排序也有递归与非递归版本,递归版实现如下代码:
果然如《数据结构与算法分析》所言,大部分人一般无法正确编写快排程序,( ╯□╰ )
1 |
|
计数排序
在基于比较的排序算法中,根据决策树分析,基于比较的排序的时间复杂度下界为O(Nlog2N)。如果需要突破该下限,则必须使用非比较型的算法,计数排序既是其中的一种。在使用计数排序时,对输入序列的范围有要求,计数排序需要额外一个数组用来保存元素出现的次数,该数组的大小为元素最大值(或者可以优化为最大值最小值范围,通过调整数组使最小元素从0开始),在保存元素出现的次数后依次把前一个元素出现次数加到后一个元素中,该值代表当前元素在排序序列中的位置,比如序列待排序序列为{0,0,2,3,4,5,6,2,3,1},通过第一步计数得到Count数组Count[0~6]={2,1,2,2,1,1,1},然后依次将前一个元素出现的次数加到后一个元素中得到Count[0~6]={2,3,5,7,8,9,10},比如Count[0]=2表示包括自己在内前面有2个元素,因此最后出现的0元素在的位置为第二个,依此类推。为了保证排序的稳定性,计数排序在最后一步排序时采用从后往前扫描的方式。由于计数排序需要Count数组以及一个附加数组保存排序后的元素,因此其空间复杂度为O(N+K),N为元素个数,K为Count数组大小。计数排序在排序过程中需要先扫描一遍整个数组,然后扫描Count数组,最后扫描整个数组回填序列,因此时间复杂度为O(2N+K)。实现代码如下所示:
1 |
|
基数排序
基数排序的基本思路和计数排序类似,不过基数排序把元素按照位数切割,对每一位进行排序比较,最后得到有序序列,由于进行了切割,其使用额外的空间大大下降,只和每位的数字取值个数有关(即进制)。基数排序方式有LSD(Least significant digital)和MSD(Most significant digital),LSD从低位到高位,MSD从高位到低位,一般而言LSD的编程方式更简单。基数排序需要进行d轮计数,每轮包括三次遍历原始数组和一次遍历计数数组,故时间复杂度为O(d(3N+r)),r为位数,空间复杂度为申请的计数数组和存放排序结果的附加数组,空间复杂度为O(N+r),具体代码如下:
1 |
|
桶排序
桶排序又称为箱排序,其基本思路是将待排序的序列分散到不同的桶中(按照大小范围,比如0~100放到一个桶中,101~200放到第二个桶中,依此类推),在每个桶中进行某种排序,最后把各个桶的结果组合起来形成最终的排序结果,在每个桶中可以采用计数排序、插入排序等排序算法,如果数组元素范围不大,每个桶可以直接采用计数排序。按照桶中排序方式不同时间复杂度差异比较大,而且是否稳定排序也和排序策略有关。桶排序最差时间复杂度可以达到O(N2),最好发生在每个桶排序时间复杂度均为线性,此时为O(N+k),k为桶的个数。桶排序的空间复杂度也和使用的底部排序算法有关,如果采用插入排序空间复杂度可以做到O(N+k),k为定义桶发生的空间消耗,以下基于插入排序和链表结构完成桶排序的算法。
1 |
|
希尔排序
希尔排序是直接插入排序的优化版,其通过将相隔一定区间的元素进行插入排序来使得元素跨越式交换,在这个过程中可能会一次交换消除多个逆序对,因此希尔排序的时间复杂度可以达到亚二次上界。希尔排序使用增量序列来进行元素跨区间插入排序,只要最后一个增量为1增可以保证最终可以得到有序的序列(增量为1退化成普通的插入排序)。增量序列的选取将会极大影响希尔排序的性能,因此不同的增量序列时间复杂度也不同,因此这里不做时间复杂度的分析,希尔排序的空间复杂度为O(1)。希尔排序由于大跨度插入,导致其排序结果是不稳定的。这里采用Donald Shell最初建议步长序列实现如下希尔排序代码(只要把插入排序稍微调整即可):
1 |
|
堆排序
堆排序采用的是二叉堆这种数据结构和不断删除堆顶元素最后得到一个有序序列的思想实现的,在建堆和删除时都可以采用一种称为下滤策略的方式及完成,因此可以将该策略做成一个单独的函数部分。在数据结构二叉堆分析中建堆过程中花费的时间为O(N),而每次删除最差时间复杂度为log2N,共需进行Nlog2N完成整个的删除,而建堆是可以在数组中原地完成的,因此其空间复杂度为O(1)。堆排序代码如下:
1 |
|
鸡尾酒排序
鸡尾酒排序是冒泡排序的一种变形,在一趟遍历中既让元素上浮也让元素下沉,其时间负复杂度和冒泡泡排序一样,其时间复杂度分析和冒泡排序类似,同时也可以通过设置标志位优化最佳排序时间复杂度,代码如下:
1 |
|
排序算法测试
上述排序代码的测试如下:
1 |
|